ICMC Supplemental Material
This page hosts supplemental material to the ICMC 2020 paper Network Modulation Synthesis: New Algorithms for Generating Musical Audio Using Autoencoder Networks.
Figures and Audio Examples
Basic network modulation synthesis example
The two audio clips below demonstrate a basic example of network modulation synthesis. The first clip is audio from the decoder using a fixed encoding. The second example uses the same parameters, but the audio is passed back through the autoencoder network. The second clip, while related to the first, differs timbrally and the encoding necessary to generate the second audio clip is likely dissimilar enough to the original encoding that it would not have been found by manipulating the original by hand (see the animated example below).
Difference in encoding parameters
In the animated GIF below, audio is generated using the time-varying encoding on the left, creating the first audio example. The audio is passed through a carrier network using network modulation synthesis and the resulting time-varying encodings are displayed on the right with the generated audio in the second clip. The audio clips are clearly related; however, the encodings are highly dissimilar, demonstrating the unintuitive and non-linear nature of the autoencoder’s encoding space. If a musician preferred the second audio to the first, network modulation synthesis provides a convenient method to discover the time-varying parameters that would be near impossible to generate by hand.
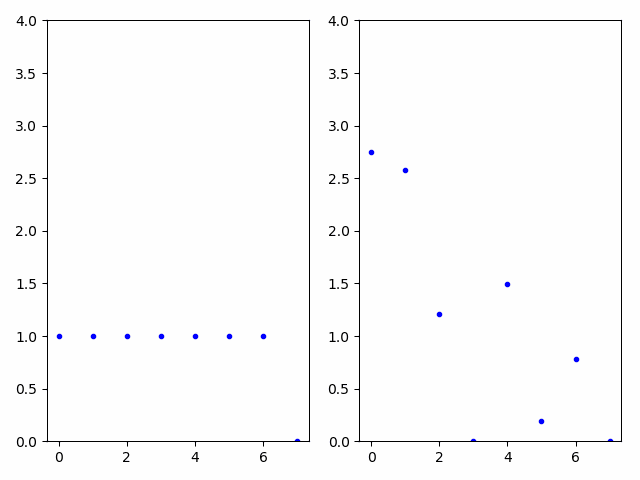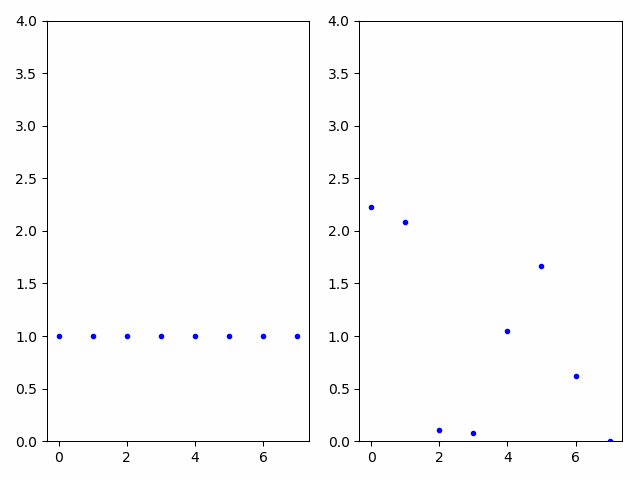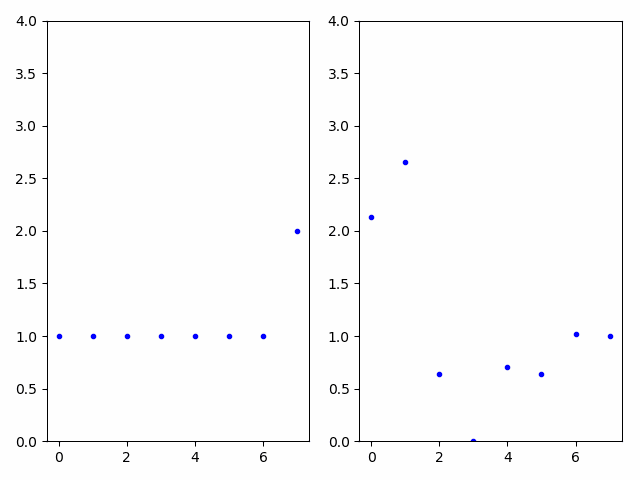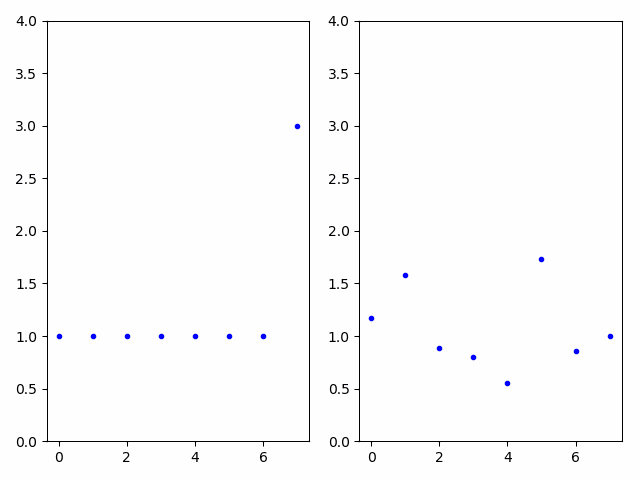
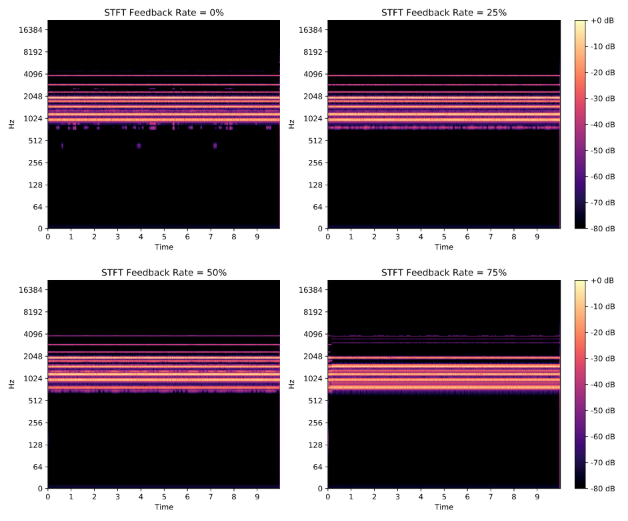
Effect of feedback
The figure below shows the spectrograms for audio created through network modulation synthesis using differing feedback amounts. Below, you can hear the original audio from the modulator (root) network and the audio from the carrier network with 0%, 25%, 50% and 75% feedback.
Predictive feedback
The figure below shows the spectrogram for 30 seconds of audio created using predictive feedback. The audio for this spectrogram is available below.

Code
All relevant code is available on Github.